



Hello, I’m Ryan Baker, today I’ll be discussing informing adaptive learning. In recent years and especially last year, there’s an explosion of data on learners and learning, as learning is needed to move online from kindergarten to corporate training, data becoming available increases considerably. A lot of data comes from interactive learning environments of various sorts. Games, like you see on the left, whether they be games where you explore a virtual environment, like you could move on top, or games where you learn physics concepts by drawing objects and they come to life, like the bottom left, physics playground. Simulation environments like ink it’s in the middle, intelligent tutoring systems and math work books like assessment on the right.

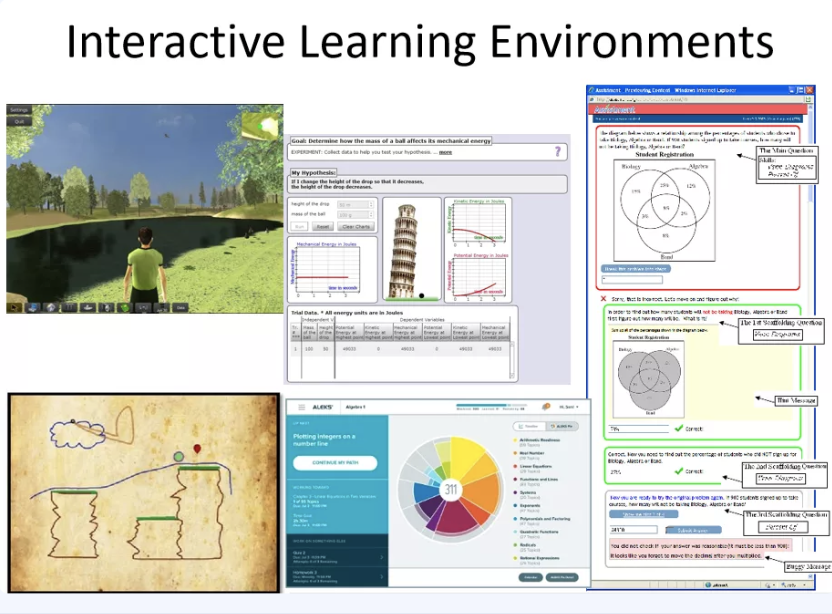

We’re collecting data from these environments, everything the learner does, but what we do with all that data to benefit students, to support instructors? People have been asking that question for about 15 years now.



Adaptive learning, which I’ll talk about for the rest of this talk, requires three things. First, determining something about the student. Second, knowing what matters, and third, doing the right thing about it.



01
Talk first about determining something about the students. There’s been quite a bit of successful work in this. What’s been achieved in academic projects still outstrips what’s available commercially.
So, some of the stuff we can infer includes learning. Has the student learned the current skill? People have been working on this problem for a couple of decades in adaptive learning and we’ve gotten pretty good algorithms.



Another category is complex learning. Is the student learning to solve complex problems that require inquiry skills? Is a student developing rich conceptual understanding in complex domains like physics and computational thinking?



Robust learning. Ideally, we don’t just wanna know what a student knows now, we wanna know if they will have it for the long term.



Metacognition. We can infer about students thinking on their own thinking. Just how confident id the student in their knowledge? Are they applying appropriate strategies and asking for help when they need it?



Disengaged behaviors, like gaming the system. We can detect when a student tries to get through learning material to succeed the material without actually learning it. And this is a behavior that I’ll talk about a little later, it associates with much worse learning.



Affect, emotion in context, emotions like boredom and frustration and confusion, and engaged concentration, curiosity.



It’s now feasible to detect all these constructs solely from students’ interaction with the learning system. Although using sensors when feasible, can increase model quality, but sensors are not feasible in all learning contexts.



How are these kinds of models developed? We first, typically through a supervised learning paradigm, classification usually, where we obtain some indicator of “ground truth”, such as existing data on student quitting or failure or performance, tests of robustness of learning or retention, self-reports, students’ self-report on emotions or attitudes, or maybe annotations by researchers of log data for strategy or behavior.



After you’ve got this ground truth, after you’ve got your training labels, use data mining to find log data indicators that could co-occur with ground truth.



After developing the models, test the model’s generalizability.

02
Once you determine something about the student, then the next step is to know what matters.





03
So, you’ve determined something about the student. You’ve figure out what matters. How do you do something about it? What do we do when we know that a student is bored or game a system or has shallow learning, or whatever? There’s a huge space of potential interventions. One such intervention, automated interventions delivered by animated agents.



Second category, stealth interventions that change learner experiences in subtle ways.



Reports to instructors, course designers, the learners themselves is another big category of intervention.

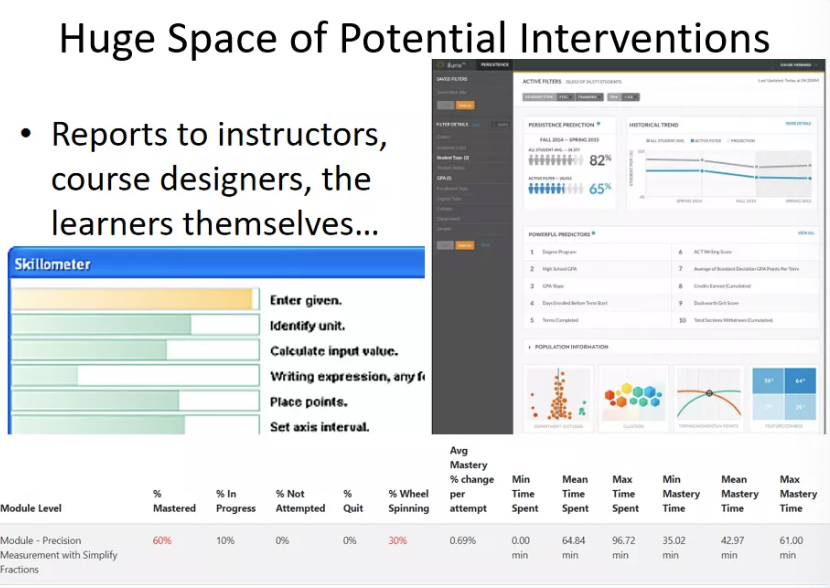

A fourth category that’s not really quite intervention, but it’s still really relevant in these models, is analyzing what content is working well or poorly.



It’s a huge space of potential interventions, lots of stuff we can do. It’s still an open area for the field. It’s an area for considerable ongoing research for my lab and many other labs.




 Address: 3663 Zhongshan North Road, Shanghai
Address: 3663 Zhongshan North Road, Shanghai Email: ecnuici@163.com
Email: ecnuici@163.com 电话:021-32526084
电话:021-32526084